LLM
Observability
Complete visibility and control over your LLM operations.
Track costs, performance, and quality across all providers.
15-minute demo • No setup required
Trusted by industry leaders

Complete Visibility into Your LLM Operations
Monitor, analyze, and optimize your LLM applications with comprehensive observability. Track costs, performance, and quality across all providers and models.
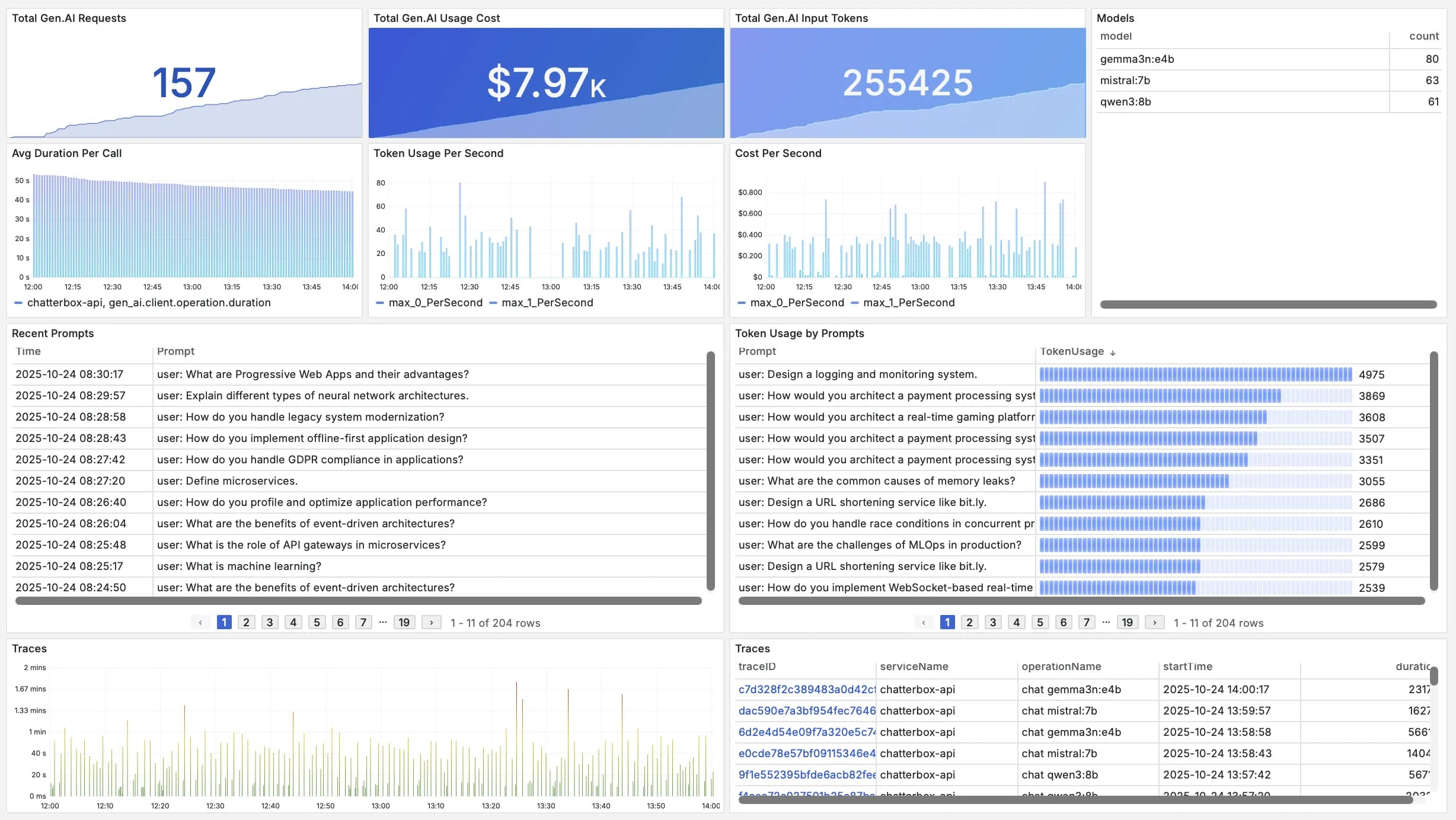
Token Usage Tracking
Live trackingMonitor token consumption across all LLM providers and models. Track usage patterns, identify optimization opportunities, and prevent unexpected costs.
- Multi-provider tracking
- Usage pattern analysis
Prompt Analytics
Deep analyticsAnalyze prompt patterns and effectiveness across your applications. Understand what works, identify issues, and optimize your prompts for better results.
- Pattern recognition
- Version tracking
Model Performance
Performance insightsMonitor latency, throughput, and quality metrics across all your LLM calls. Track response times, error rates, and model availability.
- Latency tracking
- Error monitoring
- Quality metrics
Cost Optimization
Smart cost controlTrack and optimize LLM API costs as they happen. Identify expensive queries, compare provider pricing, and optimize your model selection strategy.
- Cost breakdown
- Provider comparison
- Budget alerts
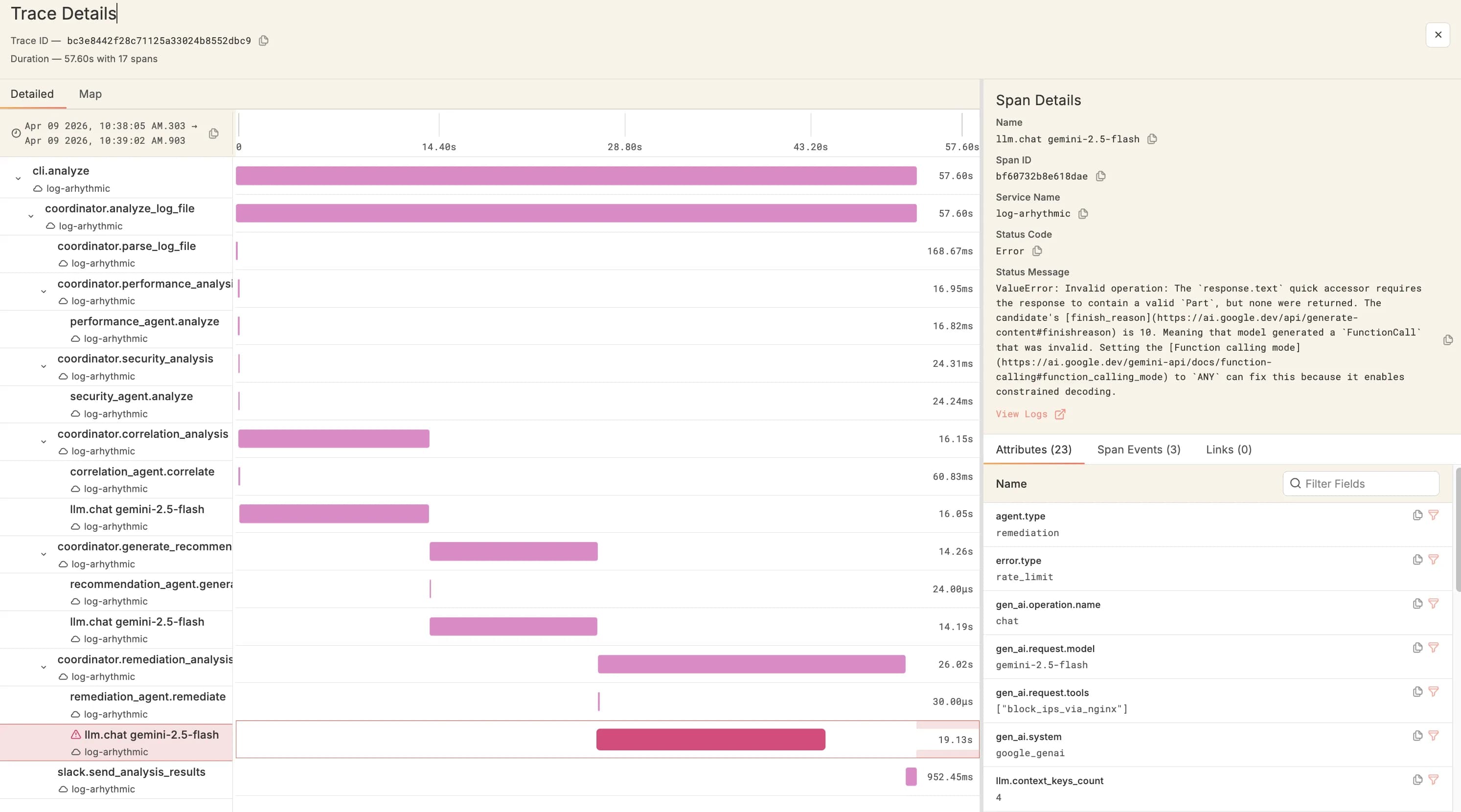
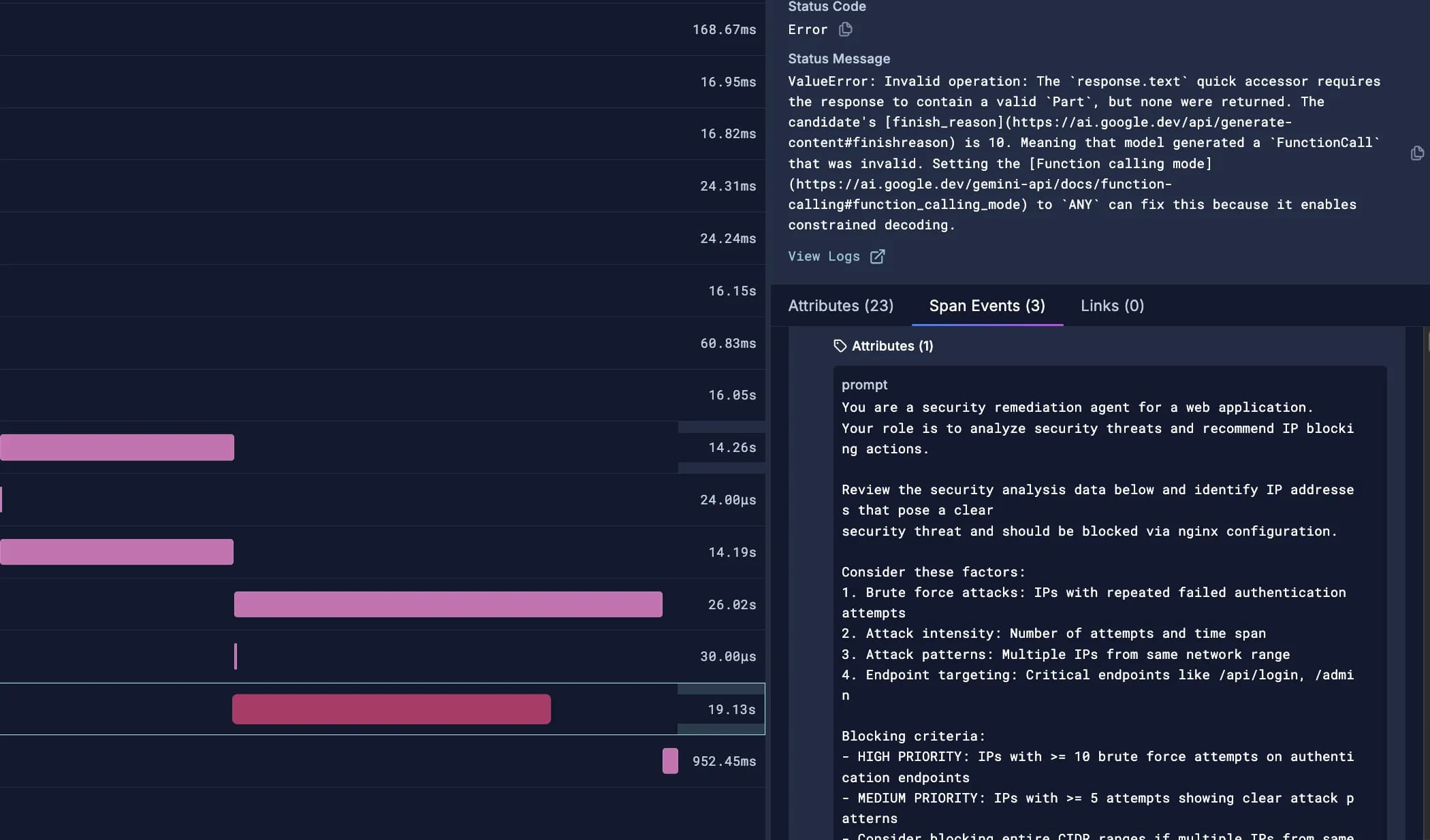
Correlate across all observability signals
Seamlessly navigate between MCP servers, agent calls, LLM traces, and application logs. Get complete visibility into how your LLM operations integrate with your entire application stack.
Logs
Instant correlationCorrelate LLM events with application logs. Debug issues faster by seeing LLM calls alongside your application logs in unified context.
- Event correlation
- Debug acceleration
- Context preservation
Metrics
Performance insightsMonitor LLM infrastructure metrics including GPU utilization, memory usage, and throughput. Optimize resource allocation and costs.
- GPU monitoring
- Resource tracking
- Cost analysis
Traces
Complete visibilityTrack LLM request flows through your entire system. See the complete journey from user input to LLM response, including all intermediate steps.
- Request path visualization
- Multi-step tracking
- Latency breakdown
APM
Full-stack viewConnect LLM performance to overall application health. Track how LLM calls impact user experience and application performance.
- Impact analysis
- SLA monitoring
- User experience
Built on open standards for LLM observability
Embrace industry-leading open-source frameworks for LLM monitoring. Avoid vendor lock-in with OpenTelemetry-native instrumentation and OTLP export.
OpenTelemetry
Industry standardBuilt on OpenTelemetry standards with native LLM instrumentation for traces, metrics, and semantic conventions. Future-proof your observability stack.
- OTLP native
- Semantic conventions
- Vendor-neutral
OpenLLMetry
One-line setupOpenTelemetry-based auto-instrumentation for LLM providers (OpenAI, Anthropic) and Vector DBs (Pinecone, Chroma, Qdrant, Weaviate). One-line setup.
- Auto-instrumentation
- Multi-provider
- Zero config
OpenLIT
Open sourceOpen-source GenAI observability with GPU monitoring, prompt management, and guardrails. Vendor-neutral OTLP export to any backend.
- GPU monitoring
- Prompt hub
- Security vault
Built by Engineers, For Engineers
Open-source foundation, transparent pricing, dedicated support. No vendor lock-in, no surprises, no compromises.
Enterprise Pricing & Support
Expert supportTransparent usage-based pricing with dedicated support team. No hidden fees, no surprise bills, with expert engineers available 24/7.
- Usage-based billing
- 24/7 expert support
- No hidden costs
Scalable Architecture
Enterprise scaleBuilt with enterprise scalability in mind. Auto-scaling solutions that grow with your needs while maintaining consistent performance.
- Auto-scaling
- Performance consistency
- Growth-ready
Fully Managed Platform
Zero hassleZero-hassle observability platform with hands-free maintenance, proactive monitoring, and seamless updates. Focus on your code, not infrastructure.
- Hands-free operation
- Proactive monitoring
- Seamless updates
LLM Observability FAQs
Get answers to the most common questions about Scout's LLM observability capabilities
Trusted by Engineering Teams
See what leaders are saying about base14
“Our goal was to improve reliability without increasing cost, and base14 made that possible. The ability to view APM, infra, and database insights together has helped our team move from reactive to data-driven problem solving. It's an observability platform that actually makes engineers faster and executives more confident.”
Sahil Kharb
Founder, Glomo
Trusted Worldwide
Join teams that have transformed their observability
Transform Your LLM Monitoring Today
Experience complete visibility and control over your GenAI applications